使用Shields为自己的项目添加微标
Shieldsio是一个提供简洁、一致和易读的徽章服务,可以轻松地包含在GitHub的readmes或其他网页中。该服务支持数十种持续集成服务、软件包注册表、分发、应用商店、社交网络、代码覆盖服务和代码分析服务。它被一些世界上最流行的开源项目使用。
根据提示,在左侧选择相关服务,
后根据实例填写右侧的信息,再按右下角Execute生成相应的链接,比如我的博客需要Markdown,则生成Markdown链接后贴到博客中即可。比如我开发的项目有:
Shieldsio是一个提供简洁、一致和易读的徽章服务,可以轻松地包含在GitHub的readmes或其他网页中。该服务支持数十种持续集成服务、软件包注册表、分发、应用商店、社交网络、代码覆盖服务和代码分析服务。它被一些世界上最流行的开源项目使用。
根据提示,在左侧选择相关服务,
后根据实例填写右侧的信息,再按右下角Execute生成相应的链接,比如我的博客需要Markdown,则生成Markdown链接后贴到博客中即可。比如我开发的项目有:
为了防止在 Linux
系统中意外删除一些重要文件或目录,除了必要的备份之外,还有一个好方法,就是使用chattr命令。
在类 Unix 等发行版中,该命令能够有效防止文件和目录被意外的删除或修改。file 文件在 Linux 中被描述为一个数据结构,chattr 命令在大多数现代 Linux 操作系统中是可用的,可以修改file属性,一旦定义文件的隐藏属性,那么该文件的拥有者和 root 用户也无权操作该文件,只能解除文件的隐藏属性。
chattr [operator] [switch] [file]
operator 具有如下操作符:
+,追加指定属性到文件已存在属性中-, 删除指定属性=,直接设置文件属性为指定属性1 | a:让文件或目录仅供附加用途; |
1 | lsattr rumenz.txt |
1 | echo "rumenz.com" rumenz.txt |
提示没有权限
i权限1 | chattr -i rumenz.txt |
1 | mkdir rumenz && touch rumenz/1.txt |
rumenz目录下创建目录1 | mkdir rumenz/one |
提示权限不足
rumenz/1.txt文件中添加数据1 | echo "rumenz.com" rumenz/1.txt |
i权限1 | chattr -i -R rumenz |
1 | lsattr rumenz.txt |
1 | echo "rumenz.com" rumenz.txt |
修改覆盖rumenz.txt文件内容不行,向后追加可以。
1 | mv rumenz.txt one.txt |
提示权限不足
rumenz目录下只能添加目录,文件,但是不能对里面的文件夹,文件修改,移动,删除。1 | chattr +a -R rumenz |
rumenz目录下创建one1 | mkdir rumenz/one |
rumenz/one目录重命名1 | mv rumenz/one rumenz/tow |
rumenz目录下创建文件1 | touch rumenz/3.txt |
rumenz/3.txt文件1 | rm -rf rumenz/3.txt |
不能被删除
rumenz/3.txt文件内容1 | echo "rumenz.com" rumenz/3.txt |
xugit(V5.2)发布2024-05-09 16:37 完成增强版xugit.sh,
安装后命令仍然为ugit. 后期如果没有重大bug,
尽量不再升级了,因为科研工作紧张。欢迎大家使用增强版xugit.sh,
欢迎反馈您的意见.
2024年05月09日,
完成了增强版U盘同步程序xugit.sh.
写这支程序的动机是为了解决文件夹误删除,同时如果被改名时能够智能找回或重建,此版采用uudi来唯一识别主机上的HOME挂载硬盘和相应的U盘,
它不依赖于U盘和仓库的名称来识别设备,所以可以自动校准电脑和U盘上的仓库,所以我称之为增强版。同时在实现逻辑上比之前的版本也进步了一大截,所以无特别需求的话,您应当下载使用增强版xugit.sh,
安装后其命令仍然为ugit,
使用ugit -h查看帮助信息。
此版,将同步网络的配置内容保存于U盘仓库,不受主机限制,所以配置一次即可走遍天下。同时,也取消了对本地~/.ugitmap的引用,专而将其建立在U盘端,这也可以避免受限于本地,所以更加合理。
增强版还优化了命令,强调易用性,对于同步的和操作实现自动化,仅保留几项常用的操作,所以它更加实用。
为了保留近二十多天的劳动成果,所以同时保存了三个版本的程序,也可以作为大家学习之用,但是未来本人将只维护xugi.sh,同时由于实现逻辑上的巨大差异,增强版xugit.sh直接升级至V5.0,
2024年05月09日版本号V5.2.
已经开发成功了ugit软件,基本实现U盘上建立GIT仓库,并且同步到不同电脑。其实现原理为:在U盘上建立仓库,然后在本地电脑写入本地目录与U盘仓库的对应关系,然后实现同步。但是这种情况存在问题也是比较严重的,下面说明:
本地仓库名称有可能被用户改变,这种情况下导致本地记录文件.ugitmap的一系列记录失效,因为这些路径不存在。
最初对本地仓库命名时,使用U盘名称@UGIT的模式,如果用户使用了另一个同名的U盘,
尽管通过比对U盘的UUID可以识别出这不是之前的源仓库,但是在本地建立仓库时就会和之前的U盘名称@UGIT冲突。
如果某用户误删除了.ugitmap文件,但是原来建立的仓库还存在,于是在执行同步的时候ugit就无法取得本地和源仓库的对应关系。
硬件设备的唯一识别编号为UUID, Linux
让的所有文件识别的唯一编号为 inode,
于是通过这两者建立一一对应关系,就不会存在ugit V4.0的问题。需要做的应当是将.ugitmap删除,同时根据硬盘UUID和U盘UUID取得一一对应关系,同时将系统中的inode自动和U盘仓库建立一一对应关系。实现流程为:
读取U盘信息,将所有插入电脑的U盘的UUID和路径存入数组变量待用。
新的U盘仓库为空时,在该U盘建立映射文件.ugitmap,
加入防删除权限。如果在U盘仓库中已经存在仓库,则使用ls命令,建立仓库路径存入数组变量待用。
.ugitmap
中记录了克隆过U盘仓库的电脑硬盘UUID和目标文件夹的inode
读对主机的硬盘信息,如果其不在.ugitmap内,此硬盘没有克隆过U盘仓库,
执行克隆操作,同时将本地上的文件夹inode记录到U盘中的.ugitmap.
如果其在.ugitmap内,则使用find按inode在/home/$USER内查找路径,建立本地map,
执行同步操作。
剩下的工作交给ugit V4.0原始程序处理。
2024-05-08 12:22 暂时记录到此。
格式化一个磁盘, 操作系统就知道您要在磁盘上存放文件了,于是系统为您将建立一个文件指针的一个结构。这个结构存放在磁盘上的起始区中的。
先前的FAT16系统占用的空间相当小,但是它所能支持的最大空间也很小的。
从WIN98后,支持的FAT32系统支持大于4G的空间。为什么会支持这样大么?就是因为它占用了更大的磁盘空间来支持文件的存储表。它是按照磁盘的空间来决定的。
我的磁盘一般是用 NTFS 系统的。因为它的安全性高一些。如果您要在局域网中存放相关的安全信息的话,那都是。而这些根目录的总体信息等等都存放在这里的。下面列出一组数据:
| U 盘容量 | 空白占用 |
|---|---|
| 105G | 93M |
| 148G | 93.8M |
| 223G | 96.7M |
git merge 和git rebase的区别, 如图
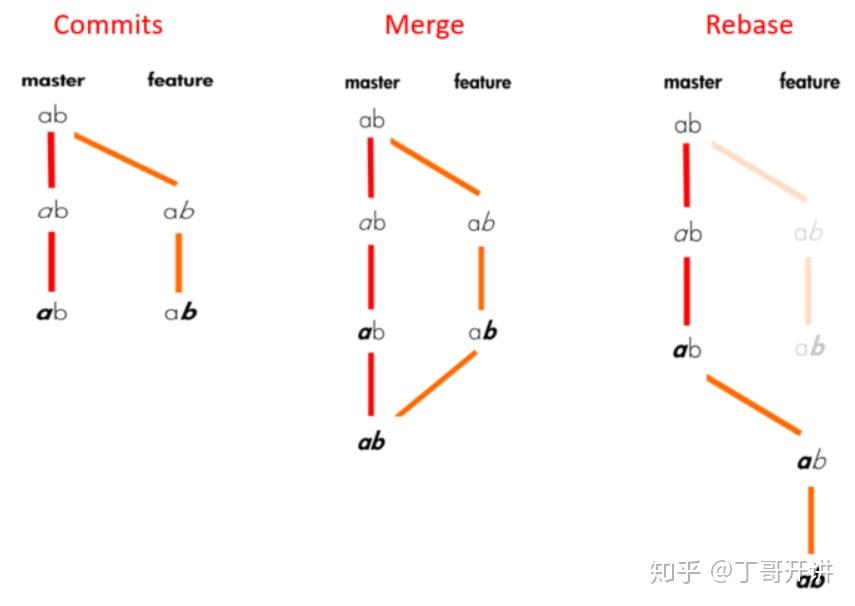
一个事情很容易判断,使用merge会得到一个复杂的路线图,但是rebase会生成一条清晰的发展路线,所以还是建议使用rebase.
之前我找到了三个工具来删除重复文件,目前的工作主力系统为archlinux,
一般选择软件的顺序为官方仓库→Aur→Github,
因为在之前的三个工具中只有fdupes是archlinux官方仓库收录的工具,所以优先安装了。今天无意间又发现一款官方工具rmlint,
它是一个命令行工具,用于在 Linux
系统中查找和删除重复的和类似 lint
的文件。它有助于识别具有相同内容的文件,以及各种形式的冗余或
lint,例如空文件、损坏的符号链接和孤立文件。使用方法:
切换到要操作的文件目录,执行rmlint,
然后它会生成一个当前目录的重复及空目录等情况列表,同时有一个脚本rmlint.sh和一个目录结构文件rmlint.json.
若要真的执行删除重复的操作,在要操作的目录中执行./rmlint.sh,
然后在弹出的提示中,输入任意内容内执行完毕。
使用教程参考rmlint doc
在编辑或修改配置文件或旧文件前,我经常会把它们备份到硬盘的某个地方,因此我如果意外地改错了这些文件,我可以从备份中恢复它们。但问题是如果我忘记清理备份文件,一段时间之后,我的磁盘会被这些大量重复文件填满 —— 我觉得要么是懒得清理这些旧文件,要么是担心可能会删掉重要文件。如果你们像我一样,在类 Unix 操作系统中,大量多版本的相同文件放在不同的备份目录,你可以使用下面的工具找到并删除重复文件。
提醒一句:
在删除重复文件的时请尽量小心。如果你不小心,也许会导致意外丢失数据。我建议你在使用这些工具的时候要特别注意。
出于本指南的目的,我将讨论下面的三个工具:
这三个工具是自由开源的,且运行在大多数类 Unix 系统中。
1. RdfindRdfind 意即 redundant data find(冗余数据查找),是一个通过访问目录和子目录来找出重复文件的自由开源的工具。它是基于文件内容而不是文件名来比较。Rdfind 使用排序算法来区分原始文件和重复文件。如果你有两个或者更多的相同文件,Rdfind 会很智能的找到原始文件并认定剩下的文件为重复文件。一旦找到副本文件,它会向你报告。你可以决定是删除还是使用硬链接或者符号(软)链接代替它们。
安装 Rdfind
Rdfind 存在于 AUR 中。因此,在基于 Arch 的系统中,你可以像下面一样使用任一如 Yay AUR 程序助手安装它。
在 Debian、Ubuntu、Linux Mint 上:
1 | $ sudo apt-get install rdfind |
在 Fedora 上:
1 | $ sudo dnf install rdfind |
在 RHEL、CentOS 上:
1 | $ sudo yum install epel-release $ sudo yum install rdfind |
用法
一旦安装完成,仅带上目录路径运行 Rdfind 命令就可以扫描重复文件。
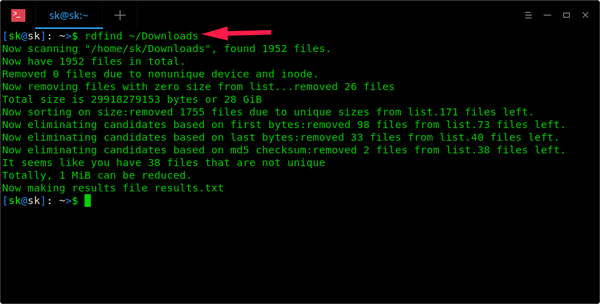
正如你看到上面的截屏,Rdfind 命令将扫描 ~/Downloads
目录,并将结果存储到当前工作目录下一个名为 results.txt
的文件中。你可以在 results.txt
文件中看到可能是重复文件的名字。
1 | $ cat results.txt # Automatically generated # duptype id depth size device inode priority name DUPTYPE_FIRST_OCCURRENCE 1469 8 9 2050 15864884 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test5.regex DUPTYPE_WITHIN_SAME_TREE -1469 8 9 2050 15864886 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test6.regex [...] DUPTYPE_FIRST_OCCURRENCE 13 0 403635 2050 15740257 1 /home/sk/Downloads/Hyperledger(1).pdf DUPTYPE_WITHIN_SAME_TREE -13 0 403635 2050 15741071 1 /home/sk/Downloads/Hyperledger.pdf # end of file |
通过检查 results.txt
文件,你可以很容易的找到那些重复文件。如果愿意你可以手动的删除它们。
此外,你可在不修改其他事情情况下使用 -dryrun
选项找出所有重复文件,并在终端上输出汇总信息。
1 | $ rdfind -dryrun true ~/Downloads |
一旦找到重复文件,你可以使用硬链接或符号链接代替他们。
使用硬链接代替所有重复文件,运行:
1 | $ rdfind -makehardlinks true ~/Downloads |
使用符号链接/软链接代替所有重复文件,运行:
1 | $ rdfind -makesymlinks true ~/Downloads |
目录中有一些空文件,也许你想忽略他们,你可以像下面一样使用
-ignoreempty 选项:
1 | $ rdfind -ignoreempty true ~/Downloads |
如果你不再想要这些旧文件,删除重复文件,而不是使用硬链接或软链接代替它们。
删除重复文件,就运行:
1 | $ rdfind -deleteduplicates true ~/Downloads |
如果你不想忽略空文件,并且和所哟重复文件一起删除。运行:
1 | $ rdfind -deleteduplicates true -ignoreempty false ~/Downloads |
更多细节,参照帮助部分:
手册页:
2. FdupesFdupes 是另一个在指定目录以及子目录中识别和移除重复文件的命令行工具。这是一个使用 C 语言编写的自由开源工具。Fdupes 通过对比文件大小、部分 MD5 签名、全部 MD5 签名,最后执行逐个字节对比校验来识别重复文件。
与 Rdfind 工具类似,Fdupes 附带非常少的选项来执行操作,如:
安装 Fdupes
Fdupes 存在于大多数 Linux 发行版的默认仓库中。
在 Arch Linux 和它的变种如 Antergos、Manjaro Linux 上,如下使用 Pacman 安装它。
在 Debian、Ubuntu、Linux Mint 上:
1 | $ sudo apt-get install fdupes |
在 Fedora 上:
1 | $ sudo dnf install fdupes |
在 RHEL、CentOS 上:
1 | $ sudo yum install epel-release $ sudo yum install fdupes |
用法
Fdupes
用法非常简单。仅运行下面的命令就可以在目录中找到重复文件,如:~/Downloads。
我系统中的样例输出:
1 | /home/sk/Downloads/Hyperledger.pdf /home/sk/Downloads/Hyperledger(1).pdf |
你可以看到,在 /home/sk/Downloads/
目录下有一个重复文件。它仅显示了父级目录中的重复文件。如何显示子目录中的重复文件?像下面一样,使用
-r 选项。
现在你将看到 /home/sk/Downloads/
目录以及子目录中的重复文件。
Fdupes 也可用来从多个目录中迅速查找重复文件。
1 | $ fdupes ~/Downloads ~/Documents/ostechnix |
你甚至可以搜索多个目录,递归搜索其中一个目录,如下:
1 | $ fdupes ~/Downloads -r ~/Documents/ostechnix |
上面的命令将搜索 ~/Downloads
目录,~/Documents/ostechnix
目录和它的子目录中的重复文件。
有时,你可能想要知道一个目录中重复文件的大小。你可以使用
-S 选项,如下:
1 | $ fdupes -S ~/Downloads 403635 bytes each: /home/sk/Downloads/Hyperledger.pdf /home/sk/Downloads/Hyperledger(1).pdf |
类似的,为了显示父目录和子目录中重复文件的大小,使用 -Sr
选项。
我们可以在计算时分别使用 -n 和 -A
选项排除空白文件以及排除隐藏文件。
1 | $ fdupes -n ~/Downloads $ fdupes -A ~/Downloads |
在搜索指定目录的重复文件时,第一个命令将排除零长度文件,后面的命令将排除隐藏文件。
汇总重复文件信息,使用 -m 选项。
1 | $ fdupes -m ~/Downloads 1 duplicate files (in 1 sets), occupying 403.6 kilobytes |
删除所有重复文件,使用 -d 选项。
样例输出:
1 | [1] /home/sk/Downloads/Hyperledger Fabric Installation.pdf [2] /home/sk/Downloads/Hyperledger Fabric Installation(1).pdf Set 1 of 1, preserve files [1 - 2, all]: |
这个命令将提示你保留还是删除所有其他重复文件。输入任一号码保留相应的文件,并删除剩下的文件。当使用这个选项的时候需要更加注意。如果不小心,你可能会删除原文件。
如果你想要每次保留每个重复文件集合的第一个文件,且无提示的删除其他文件,使用
-dN 选项(不推荐)。
当遇到重复文件时删除它们,使用 -I 标志。
关于 Fdupes 的更多细节,查看帮助部分和 man 页面。
1 | $ fdupes --help $ man fdupes |
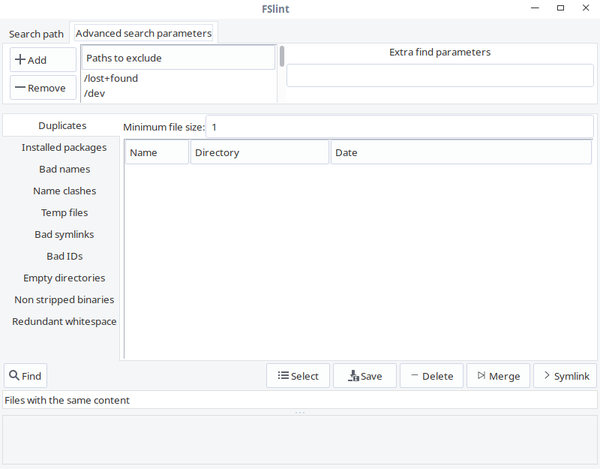
3. FSlintFSlint 是另外一个查找重复文件的工具,有时我用它去掉 Linux 系统中不需要的重复文件并释放磁盘空间。不像另外两个工具,FSlint 有 GUI 和 CLI 两种模式。因此对于新手来说它更友好。FSlint 不仅仅找出重复文件,也找出坏符号链接、坏名字文件、临时文件、坏的用户 ID、空目录和非精简的二进制文件等等。
安装 FSlint
FSlint 存在于 AUR,因此你可以使用任一 AUR 助手安装它。
在 Debian、Ubuntu、Linux Mint 上:
1 | $ sudo apt-get install fslint |
在 Fedora 上:
1 | $ sudo dnf install fslint |
在 RHEL,CentOS 上:
1 | $ sudo yum install epel-release $ sudo yum install fslint |
一旦安装完成,从菜单或者应用程序启动器启动它。
FSlint GUI 展示如下:
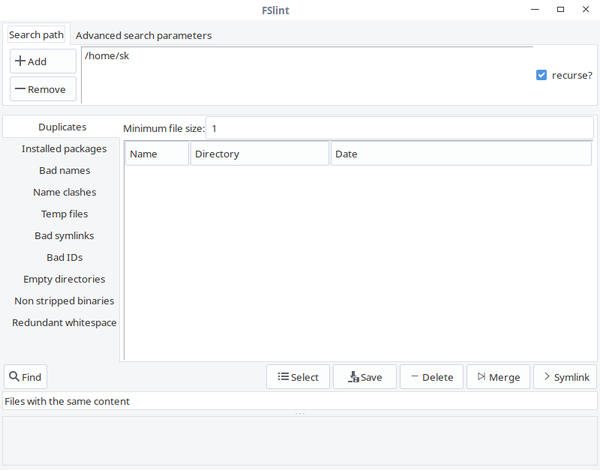
如你所见,FSlint 界面友好、一目了然。在 “Search path” 栏,添加你要扫描的目录路径,点击左下角 “Find” 按钮查找重复文件。验证递归选项可以在目录和子目录中递归的搜索重复文件。FSlint 将快速的扫描给定的目录并列出重复文件。
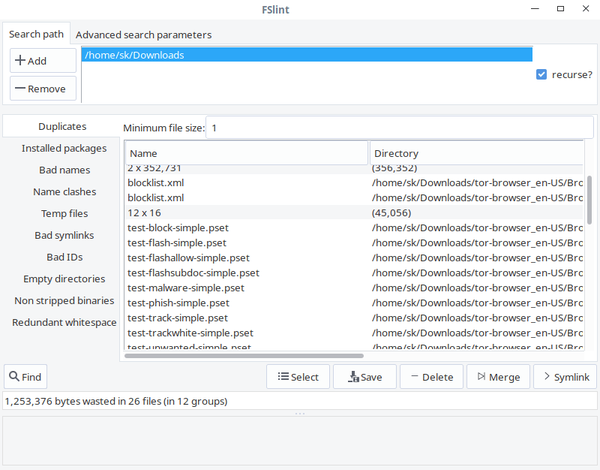
从列表中选择那些要清理的重复文件,也可以选择 “Save”、“Delete”、“Merge” 和 “Symlink” 操作他们。
在 “Advanced search parameters” 栏,你可以在搜索重复文件的时候指定排除的路径。
FSlint 命令行选项
FSlint 提供下面的 CLI 工具集在你的文件系统中查找重复文件。
findup — 查找重复文件findnl — 查找名称规范(有问题的文件名)findu8 — 查找非法的 utf8 编码的文件名findbl — 查找坏链接(有问题的符号链接)findsn — 查找同名文件(可能有冲突的文件名)finded — 查找空目录findid — 查找死用户的文件findns — 查找非精简的可执行文件findrs — 查找文件名中多余的空白findtf — 查找临时文件findul — 查找可能未使用的库zipdir — 回收 ext2 目录项下浪费的空间所有这些工具位于 /usr/share/fslint/fslint/fslint
下面。
例如,在给定的目录中查找重复文件,运行:
1 | $ /usr/share/fslint/fslint/findup ~/Downloads/ |
类似的,找出空目录命令是:
1 | $ /usr/share/fslint/fslint/finded ~/Downloads/ |
获取每个工具更多细节,例如:findup,运行:
1 | $ /usr/share/fslint/fslint/findup --help |
关于 FSlint 的更多细节,参照帮助部分和 man 页。
1 | $ /usr/share/fslint/fslint/fslint --help $ man fslint |
总结
现在你知道在 Linux 中,使用三个工具来查找和删除不需要的重复文件。这三个工具中,我经常使用 Rdfind。这并不意味着其他的两个工具效率低下,因为到目前为止我更喜欢 Rdfind。
作为一名物理学工作者,输入大量的LaTeX公式不可避免,然后为了节省输入时间,以及输入的规范化,本文介绍三个标准的宏包,希望能够为您的工作增效。
具体使用说明,安装Texlive后,请执行:texdoc physics
等。
physics The goal of this package is to make typesetting equations for physics simpler, faster, and more human readable. To that end, the commands included in this package have names that make the purpose of each command immediately obvious and remove any ambiguity while reading and editing physics code. From a practical standpoint, it is handy to have a well-defined set of shortcuts for accessing the long-form of each of these commands. The commands listed below are therefore defined in terms of their long-form names and then shown explicitly in terms of the default shorthand command sequences. These shorthand commands are meant make it easy to remember both the shorthand names and what each one represents.
physconst This package consists of several macros that are shorthand for a variety of physical constants, e.g. the speed of light. The package developed out of physics and astronomy classes that I have taught and wanted to ensure that I had correct values for each constant and did not wish to retype them every time I use them. The constants can be used in two forms, the most accurate available values, or versions that are rounded to 3 significant digits for use in typical classroom settings, homework assignments, etc.
physunits This package consists of several macros that are shorthand for a variety of physical units that are commonly used in introductory level physics and astronomy classes. At present, this package provides some similar units to those in siunitx, but is uses slightly different macro names for each. This package also provides a number of non-SI units (e.g. erg, cm, BTU).
若文章中几处需要添加相同内容的脚注,各自都写\footnote{*}的话,则会出现好几个内容重复的脚注。这个问题可以通过“标签引用”+“上标”来解决。比如我们要给ORL和Jaffe都添加同样的脚注,可以这样:
1 | ORL\footnote{http://blog.csdn.net/bear\_kai\label{web}} and |
注意网址中有下划线时,在latex中需要额外加一个反斜杠即“转义字符”。
默认情况下 pip 使用的是国外的镜像,在下载的时候速度非常慢,本文我们介绍使用国内清华大学的源,地址为:
1 | https://pypi.tuna.tsinghua.edu.cn/simple |
我们可以直接在 pip 命令中使用 -i
参数来指定镜像地址,例如:
1 | pip3 install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple |
以上命令使用清华镜像源安装 numpy 包。这种只对当前安装对命令有用,如果需要全局修改,则需要修改配置文件。
Linux/Mac os 环境中,配置文件位置在 ~/.pip/pip.conf(如果不存在创建该目录和文件):
1 | mkdir ~/.pip |
打开配置文件 ~/.pip/pip.conf,修改如下:
1 | [global] |
查看 镜像地址:
1 | $ pip3 config list |
可以看到已经成功修改了镜像。
Windows下,你需要在当前对用户目录下(C:\\Users\\xx\\pip,xx
表示当前使用对用户,比如张三)创建一个
pip.ini在pip.ini文件中输入以下内容:
1 | [global] |